|
Currently I work as a staff research scientist with SenseTime Research. At SenseTime I've worked on SensePhoto, the state-of-the-art mobile photography solution dilivered to major smartphone OEMs. I earned my PhD at Beihang University, advised by Prof. Qinping Zhao and Prof. Bin Zhou. I also work as a visiting researcher at CVTEAM led by Prof. Jia Li. I did postdoc from 2019 to 2021, advised by Prof. Xiaogang Wang and Yebin Liu. Email / CV / Bio / Google Scholar |

|
|
I study computer vision, event-based vision, machine learning and optimization. My research lies much in image and video processing with learning and optimization methods. (†interns/students *corresponding author) |

|
Zhiyang Yu†, Yu Zhang*, Xujie Xiang, Dongqing Zou, Xijun Chen, Jimmy S. Ren ECCV, 2022 paper / code By encoding the VFI prior into a few unfolded, learned gradient descent steps under the Bayesian regularization framework, our new VFI model achieves state-of-the-art results with only half the parameters of existing models, while showing better generalizability. |

|
Yifan Zhao, Jia Li, Yu, Zhang, Yonghong Tian IEEE TPAMI, 2022 paper / code Human part segmentation can be conducted without dense pixel-level annotations by evolving a coarse part class map with image boundary cues, constrained by pose and object-level annotations. |

|
Zhiyang Yu†, Yu Zhang*, Deyuan Liu, Dongqing Zou, Xijun Chen, Yebin Liu. Jimmy S. Ren ICCV, 2021 paper/ code Using an event camera allows you to train video interpolation models without the need of high frame-rate videos. |
 
|
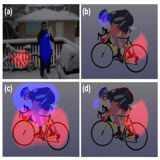
Daxin Gu†, Jia Li, Yu, Zhang*, Yonghong Tian ACM MM, 2021 (Oral Presentation) paper / code A fully trainable white-box event camera simulator with divide-and-conquer domain adaptation that automatically calibrate its parameters towards target domain. |
|
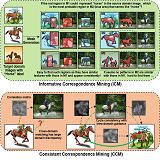
Luwei Hou†, Yu, Zhang*, Kui Fu, Jia Li CVPR, 2021 (Oral Presentation) paper / supp. Cross-domain pixel-level correspondences can be learned in weakly supervised manner for object detector adaptation. |
 
|
Song Zhang†, Yu Zhang*, Zhe Jiang†, Dongqing Zou, Jimmy S. Ren, Bin Zhou ECCV, 2020 paper / code Unpaired image translation from low light to day light can be achieved by the HDR of event streams captured by an event camera. |

|
Kui Fu, Jia Li, Yu Zhang, Hongze Shen, Yonghong Tian TIP, 2020 paper / dataset(ID:3yd8,password:cvteam) A dataset for aerial saliency detection and how to adapt existing saliency models to this task. |
|
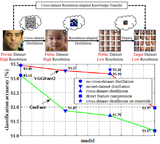
Shiming Ge, Shengwei Zhao, Chenyu Li, Yu Zhang, Jia Li TIP, 2020 paper Simply learning feature super-resolution and knowledge distillation in multi-task way produces an accurate face detector capable of processing 763 faces/s on mobile phone. |

|
Zhe Jiang†*, Yu Zhang*, Dongqing Zou, Jimmy S. Ren, Jiancheng Lv, Yebin Liu CVPR, 2020 paper / code An end-to-end learning pipeline that restores a motion blurred image to a video sequence using event camera. |

|
Yifan Zhao, Jia Li, Yu Zhang, Yafei Song, Yonghong Tian TPAMI, 2020 paper Useful context information can be mined by optimizing the processing order of parts in semantic part parsing. |
 
|
Yifan Zhao, Jia Li, Yu Zhang, Yonghong Tian ICCV, 2019 (Oral Presentation) project page / paper Semantic part parsing benefits from jointly processing multiple classes by attending to part boundaries and class discrimination. |
 
|
Jinming Su, Jia Li, Yu Zhang, Changqun Xia Yonghong Tian ICCV, 2019 project page / paper Modeling the transitions across object boundaries helps salient object segmentation. |
 
|
Cross-Reference Stitching Quality Assessment for 360𛲕 Omnidirectional Images
Jia Li, Kaiwen Yu, Yifan Zhao, Yu Zhang, Long Xu ACM MM, 2019 (Oral Presentation) project page / paper A new dataset for omnidirectional image stitching and novel metrics for assessing the quality of related algorithms. |
 
|
Yu Zhang, Dongqing Zou, Jimmy S. Ren, Zhe Jiang, Xiaohao Chen CVPR, 2019 paper / supp. Multiscale adversarial training on feature correlations defines unsupervised structural preservation loss for novel view synthesize. |
 
|
Feixiang Lu, Bin Zhou, Yu Zhang, Qinping Zhao TVC, 2018 (Best Paper Award of CGI 2018) paper By improving reference frame selection and 6D pose prediction, we reconstruct dynamic objects in real-time while handling large motion. |

|
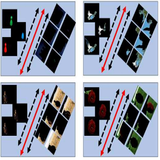
Yu Zhang, Xiaowu Chen, Jia Li, Wei Teng, Haokun Song TIP, 2018 paper / results Modeling object part relations with simple priors enables accurate object localization in videos with weak supervision. |
|
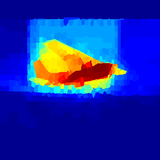
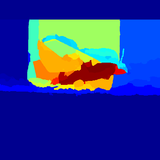
Changqun Xia, Jia Li, Xiaowu Chen, Anlin Zheng, Yu Zhang CVPR, 2017 (Spotlight) project / paper / results / data Exemplar detectors are explored to learn instance-specific saliency patterns and a large saliency detection dataset is proposed. |
|
Yu Zhang, Xiaowu Chen, Jia Li, Chen Wang, Changqun Xia, Jun Li TPAMI, 2017 paper Extended version of CVPR 2015 with improved network flow solver and object shape prior. |
|
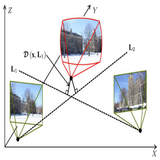
Yafei Song, Xiaowu Chen, Xiaogang Wang, Yu Zhang, Jia Li TMM, 2016 (Best Paper Award of IEEE BigMM 2015) paper Searching for the posed images with appearance similar to the input image can uniquely determine its pose with fast inference. |
|
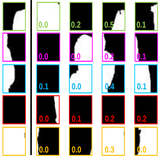
Wei Teng*, Yu Zhang*, Xiaowu Chen, Jia Li, Zhiqiang He BMVC, 2016 (Oral Presentation) paper / extended abstract Shapes of local image patches lie in low-dimensional manifold, which is a consistency regularizer for image co-segmentation. |
 
|
Han Zhang, Xiaowu Chen, Yu Zhang, Jia Li, Qing Li, Xiaogang Wang ICME, 2015 paper By incorporating global layout consistency modelled with maximum weighted clique, previous detection rate of cuboid proposals in RGBD images is doubled. |

|
Yu Zhang, Xiaowu Chen, Jia Li, Chen Wang, Changqun Xia CVPR, 2015 (Oral Presentation) paper Weak object detectors can generate strong video object segmentation results via joint inference with a quadratic network flow model. |

|
Qing Li, Xiaowu Chen, Yafei Song, Yu Zhang TIP, 2014 paper We present a fast approach for semantic segmentation by propagating labels along geodesic paths in feature space. |
|
Yu Shi, Undergraduate student from Peking University, internship 2021-2022. Now a graduate student at UCLA. Zhe Jiang, Master student from Sichuan University, intership 2018-2020. CVPR 2020 and ECCV 2020. Now a PhD student at The Hong Kong Polytechnic University. Song Zhang, Master student from Beihang University, intership 2018-2020. ECCV 2020. Now a researcher at SenseTime. Luwei Hou, Master student from Beihang University, intership 2020-2021. CVPR 2021. Now a researcher at SenseTime. |
|
Much thanks to Jon Barron for sharing this template. |